
The Role of Link Functions in Generalized Linear Models
You will learn the transformative role of Link Functions in Generalized Linear Models for precise data interpretation.
Introduction
Generalized Linear Models (GLMs) extend traditional linear regression to accommodate various data distributions, with link functions central to their application. These functions transform the linear model output to the scale of the response variable, ensuring appropriate predictions across different data types. The focus here is on the critical role of understanding link functions within GLMs, as their proper use is essential for model accuracy and interpretability, making them indispensable in statistical modeling and data analysis.
Highlights
- The logit link function is ideal for binary outcome modeling.
- Identity link suits continuous data in linear regression.
- The probit link function is used for probit regression models.
- Link functions ensure that model predictions match the response variable scale.
- Choosing the correct link function improves model fit and accuracy.
Ad Title
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Understanding Link Functions in Generalized Linear Models
Generalized Linear Models (GLMs) represent an extension of traditional linear regression models designed to accommodate a wide array of data types and distribution patterns. At their core, GLMs consist of three principal components:
- The random component specifies the probability distribution of the response variable;
- The systematic component relates the predictors to the response through a linear predictor function;
- The link function connects the distribution’s mean with the linear predictor (the focus of our article).
In GLMs, link functions are essential mathematical tools that connect the linear predictor (a combination of coefficients and predictor variables) to the mean of the response variable. Their primary purpose is to ensure the linearity of the model, regardless of the type of the response variable involved, which can range from binary to count data, among others.
A link function operates by transforming the expected value of the response variable to a scale where a linear relationship with the predictors can be established. This transformation is crucial because it allows the model to accommodate response variables that do not naturally fit a linear scale, such as probabilities between 0 and 1 in logistic regression. For instance, in a logistic regression model, the logit link function transforms the probability scale to an unbounded scale, where linear regression can be applied.
The transformation carried out by link functions has profound implications for model interpretation and prediction. It ensures that predictions are mathematically sound and meaningful in the context of the data’s original scale. For example, by applying the inverse of the link function, predictions made on the transformed scale can be converted back to the original scale of the response variable, thus making them interpretable and actionable.
In summary, link functions are pivotal in extending the flexibility and applicability of linear models to a wide array of data types and distributions, thereby enhancing the robustness and utility of statistical modeling in data analysis.
Types of Link Functions in Generalized Linear Models
Generalized Linear Models (GLMs) use a variety of link functions to relate the linear predictor to the response variable’s mean. The choice of function is contingent upon the data distribution and the analysis goals. Common link functions and their typical applications include:
Identity: This link function is the simplest, as it does not transform the predictor variables. It’s typically used when the response variable is expected to have a normal distribution, and the variance is constant across levels of the predictor variables. The identity function is ideal for cases where the scale of the measurements taken matches the scale of the predictions desired, such as predicting heights or weights.
Logit: The logit function is central to logistic regression, where the outcome is categorical with two possible outcomes (e.g., yes/no, success/failure). The logit link models the logarithm of the odds of the default category. This function is handy because the resulting coefficients can be interpreted as changes in the log odds of the outcome per unit change in the predictor.
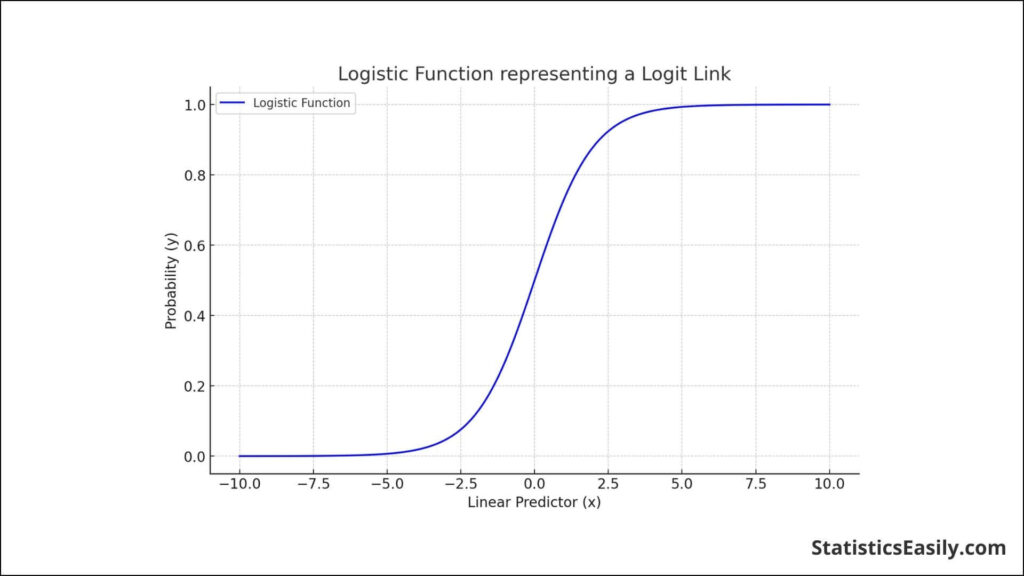
Probit: Used in probit regression, the probit link function is similar to the logit, but it assumes that the error terms of the latent variable follow a normal distribution. This link is especially advantageous when dealing with latent variables or when a normal probability plot of the residuals is desired.
Log: In Poisson regression and other count data models, the log link function is used to model count data ranging from zero to positive infinity. It is particularly effective because it can handle the skewness typically associated with count data and provides a natural logarithmic transformation.
Inverse: This link function is used when the response variable is expected to change at a rate inversely proportional to the value of the predictors. An example would be the speed of completing a task, which might decrease (get slower) as the difficulty or complexity of the task increases.
Inverse Squared: Useful in cases where the response variable is proportional to the inverse square of the predictor variable. It is less commonly used but can be appropriate for specific physical processes or rate phenomena where the effect of the predictor decreases with its square.
Square Root: The square root link function can be appropriate for count data, mainly when dealing with variances that are not constant but are proportional to the mean of the count. It is a variance-stabilizing transformation, often applied in cases where data follow a Poisson distribution with a mean that increases with the variance.
Power Functions: Power functions encompass a family of transformations, including square, cube, and fractional powers of the predictors. These are used when the relationship between the response and the predictor variables is polynomial or when the variance of the response increases with its mean. They provide a flexible approach to modeling complex relationships in GLMs.
Incorporating these link functions expands the versatility of GLMs, allowing them to model complex, non-linear relationships in a linear framework. The choice of a link function is a decisive factor in the model’s ability to accurately reflect the data and provide interpretable results. It is essential to understand the distribution of your data and the substantive meaning of your model’s predictors to select the most appropriate link function. This selection can significantly impact the model’s predictive performance and the validity of its conclusions, reinforcing the importance of a thorough understanding of each link function’s characteristics and applications.
Application of Link Functions in Generalized Linear Models
The application of link functions within Generalized Linear Models (GLMs) is a process that involves the careful selection and implementation of the appropriate transformation to connect the linear predictor to the response variable. Below is a step-by-step guide on applying these functions, along with examples in R and Python, two of the most widely used programming languages in statistics and data science.
Step-by-Step Guide:
1. Identify the Distribution of the Response Variable: Determine the nature of your response variable (binary, count, continuous, etc.) and its distribution (binomial, Poisson, normal, etc.).
2. Choose the Appropriate Link Function: Select a link function corresponding to the response variable’s distribution and nature. Use the information from the “Types of Link Functions” section as a guide.
3. Gather Your Data: Ensure your data is clean and formatted correctly for analysis in your chosen statistical software.
4. Load Your Data into R or Python: Use appropriate functions to read your data into an R dataframe or a Python pandas dataframe.
5. Fit the GLM Model: Use the ‘glm()’ function in R or the ‘statsmodels’ library in Python to fit your model. Specify the distribution’s response variable, predictors, link function, and family.
6. Check Model Diagnostics: After fitting the model, evaluate its performance by checking residuals and other diagnostics to ensure its assumptions are met.
7. Interpret the Results: Analyze the output, paying close attention to the coefficients, their significance, and the model’s overall fit to draw meaningful conclusions.
8. Report the Findings: Present your results clearly and interpretably, making sure to back up your conclusions with statistical evidence.
Examples in R and Python:
R Example:
# Load the necessary library library(stats) # Fit a GLM model with a binomial family and logit link function model <- glm(response_variable ~ predictor1 + predictor2, family = binomial(link = "logit"), data = your_data_frame) # Summarize the model summary(model) # Get the fitted probabilities fitted_results <- predict(model, type = "response") # Model diagnostics can be performed here
Python Example:
import pandas as pd
import statsmodels.api as sm
# Load your data
data = pd.read_csv('your_data.csv')
# Define the model, using the logit function for a binary outcome
model = sm.GLM(data['response_variable'], data[['predictor1', 'predictor2']], family=sm.families.Binomial(link=sm.families.links.logit()))
# Fit the model
results = model.fit()
# Summarize the model output
print(results.summary())
# Get the fitted values
fitted_values = results.predict()
# Model diagnostics can be performed here
It is important to remember that model diagnostics and validation are as crucial as the initial fitting process. Ensuring your model is well-fitted to your data enhances its predictive accuracy and ensures the integrity and reliability of your analytical conclusions.
Advantages of Using the Correct Link Function in Generalized Linear Models
Selecting the appropriate link function for Generalized Linear Models (GLMs) is not merely a statistical formality; it is a decision that profoundly impacts the accuracy of the model and the validity of its interpretation. The use of the correct link function aligns the model with the underlying data structure, which results in several key advantages:
Impact on Model Accuracy:
Consistent Predictions: The correct link function ensures that predictions are consistent with the distribution of the response variable, enhancing model reliability.
Appropriate Scale: It maps the predictions to an appropriate scale, which is crucial for response variables that are not normally distributed or are bounded within a specific range.
Reduced Bias: Matching the link function to the data reduces bias in parameter estimates, leading to more accurate predictions and a better understanding of the predictor variables’ effects.
Goodness of Fit: A model with the correct link function often shows improved goodness-of-fit statistics, indicating that the model adequately captures the relationship between the predictors and the response variable.
Real-world Implications:
Interpretability: Correct link functions facilitate a more straightforward interpretation of the model parameters, which can be crucial for making informed decisions based on the model’s outputs.
Decision Making: In fields like medicine, economics, and public policy, the ability to interpret model outputs correctly can influence critical decisions that affect real-world outcomes.
Resource Allocation: For businesses and organizations, accurate models can guide the efficient allocation of resources by predicting outcomes such as risk, demand, and growth more precisely.
Scientific Insights: In research, using the appropriate link function can uncover significant associations and causal relationships that might otherwise be obscured, leading to new scientific insights and advancements.
In essence, the correct link function is fundamental to the integrity of a GLM. It bridges the theoretical with the practical, ensuring that statistical analyses produce meaningful, actionable results that reflect the complex reality of the data. By meticulously aligning the link function with the nature of the data, statisticians and data scientists can deliver analyses that resonate with mathematical correctness and with the truth of the phenomena under study.
Ad Title
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Conclusion
In summary, the strategic use of link functions in Generalized Linear Models (GLMs) is vital for accurate data analysis and interpretation, serving as the crucial connection between statistical theory and real-world application. They empower us to adeptly model and interpret diverse data types, enriching our insights and guiding informed decisions across various disciplines. As we conclude, it’s clear that delving deeper into the nuances of GLMs and link functions is beneficial and essential for anyone looking to master the art and science of data analysis.
Recommended Articles
Delve deeper into statistical modeling by exploring our comprehensive guides on related topics here. Enhance your data analysis skills today!
- Navigating the Basics of Generalized Linear Models: A Comprehensive Introduction
- Generalized Linear Model (GAM) Distribution and Link Function Selection Guide
- Understanding Distributions of Generalized Linear Models
- The Role of Link Functions in Generalized Linear Models
Frequently Asked Questions (FAQs)
Q1: What defines Generalized Linear Models (GLMs) in statistical analysis? GLMs are versatile frameworks that expand the capabilities of linear models to embrace various response variable distributions, using link functions as their core transformative tool.
Q2: Why do link functions play a critical role in the structure of GLMs? Link functions are the linchpins of GLMs, enabling the linear predictor to communicate effectively with the mean of the response variable across diverse distributions.
Q3: Which link function is a staple for binary outcome analysis? The logit link function is the cornerstone for binary outcomes, offering a profound insight into the relationship between predictor variables and binary response probabilities.
Q4: How are link functions utilized in modeling count data? For count data, link functions like the log link in Poisson regression models address the distribution’s skewness, allowing for accurate representation and analysis.
Q5: In what ways do link functions influence the interpretation of GLM results? Link functions shape the prediction scale, directly affecting the interpretability of coefficients and the overall model outcome, thereby guiding meaningful conclusions.
Q6: Are link functions tailored to specific data types in GLMs? Link functions are meticulously chosen based on the response variable’s distribution and the analytical objectives, ensuring precise modeling in GLMs.
Q7: How do the logit and probit link functions differ in their application? While both address binary outcomes, the logit link hinges on a logistic distribution. In contrast, the probit link is grounded in the normal distribution, each providing unique insights into the data’s structure.
Q8: What criteria guide the selection of the proper link function in a GLM? The choice of a link function is determined by the nature of the response variable’s distribution and the interpretive framework desired for the model coefficients.
Q9: Is integrating multiple link functions within a single GLM possible? Typically, a single link function is used per model; however, complex GLMs may incorporate multiple link functions to capture the nuances of the data accurately.
Q10: Do software environments influence the implementation of link functions in GLMs? Yes, the specification and application of link functions can vary across statistical software, necessitating a thorough understanding of the software’s functionality for optimal model fitting.





