
Accuracy, Precision, Recall, or F1: Which Metric Prevails?
You will learn the crucial differences between accuracy, precision, recall, and F1 to choose the right evaluation metric.
Introduction
In data science and predictive modeling, accurately measuring a model’s performance is as crucial as pursuing the model itself. Yet, amidst a sea of metrics — accuracy, precision, recall, and F1 — choosing the one that truly aligns with the objective of your analysis remains a nuanced challenge.
You may ponder, “Which metric best serves the truth of my model’s predictive power?” This decision holds profound implications, not just for the integrity of your model but for the real-world consequences that hinge on its predictions.
Consider the healthcare industry, where a model’s ability to predict disease can be a matter of life and death. Here, the choice of metric transcends mere numbers — it becomes a testament to the value we place on human life and wellbeing. In such a context, does accuracy alone suffice when it overlooks a false negative, a patient wrongly assessed as disease-free?
Or, consider the field of financial fraud detection. What use is an accurate model if it fails to flag fraudulent transactions, mistaking them for legitimate activities? The repercussions are not just monetary losses but a shake to the foundation of trust upon which the financial system rests.
In the following sections, we shall dissect each metric with precision, unravel the contexts where each metric shines, and ultimately equip you with the discernment to select a metric that reflects the efficacy of your model and resonates with the ethical imperatives of your work.
Highlights
- Accuracy can be misleading; a 99.9% score might ignore significant false negatives.
- Precision measures how many predicted positives are true, which is essential in spam detection.
- Recall calculates the capture rate of actual positives, which is vital in fraud and illness detection.
- The F1 score balances precision and recall, which is helpful in uneven class distributions.
- Choosing metrics depends on context; no single metric suits all situations.
Ad Title
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
The Pitfalls of Relying Solely on Accuracy
Accuracy is often heralded as the quintessential measure of a model’s performance, an apparent testament to its predictive prowess. But does it tell the whole story? Let’s delve into the confusion matrix, a tableau for the true versus the predicted, to uncover the truth behind the numbers.
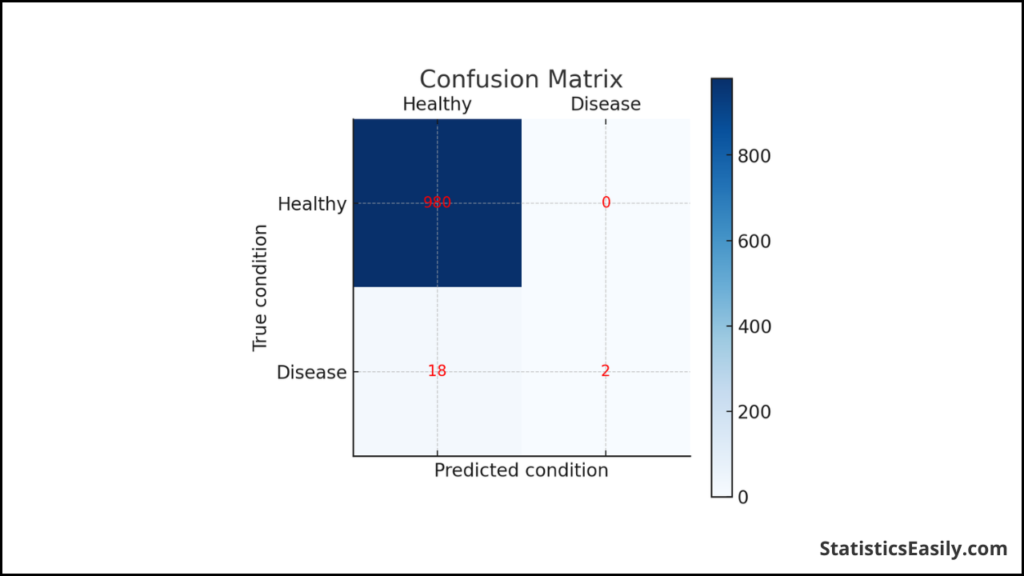
Here is a hypothetical confusion matrix for a disease prediction model:
| True Condition | Predicted Healthy | Predicted Disease |
|---|---|---|
| Healthy | 980 | 0 |
| Disease | 18 | 2 |
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actual Negative | True Negative | False Positive |
| Actual Positive | False Negative | True Positive |
At first glance, an accuracy of 98.2% might seem commendable. Yet, this single metric masks a grave reality. Out of 20 actual disease cases, the model failed to identify 18. These false negatives carry a high misclassification cost — undetected untreated, their condition could worsen, or they could unknowingly spread the illness.
Imagine the implications in a real-world scenario: a contagious disease outbreak where early detection is paramount. A model with such an accuracy rate could lead to a public health disaster. In this case, the accuracy metric is not just misleading; it’s potentially dangerous.
Accuracy lulls us into a false sense of security, obscuring the critical failures that can lead to dire consequences. Accuracy alone is insufficient in contexts where the cost of a false negative is high, such as in healthcare or cybersecurity. We must look beyond metrics that consider the weight of each misclassification to guide us toward a model that not only predicts but protects.
Precision – The Art of Being Specific
Precision emerges as a crucial metric in the pursuit of a model’s performance, particularly in scenarios where the cost of a false positive is high. Precision is the proportion of true positives against all predicted positives — it measures the exactness of a model in identifying only relevant instances.
Consider a spam detection system; an email incorrectly flagged as spam (false positive) can mean missing a crucial communication. Here, precision becomes the safeguard against such costly errors. It is not merely about catching all spam but ensuring that legitimate emails are not lost.
The formula for precision is a simple yet profound expression:
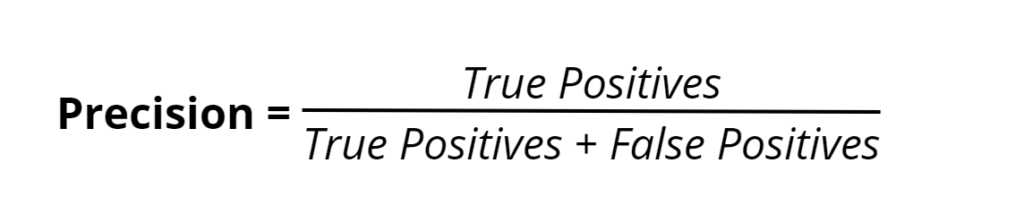
This translates to the share of actual positives out of all the instances the model labeled as positive. In our earlier healthcare example, a high-precision model would correctly identify patients with the disease and minimize those wrongly diagnosed, maintaining trust in the medical diagnosis process.
The stakes are high in fields like finance, where a false positive could mean a legitimate transaction being flagged as fraudulent. Precision ensures that everyday transactions are not obstructed, reflecting the model’s capacity to uphold operational integrity and ethical responsibility towards stakeholders.
Thus, while accuracy gives us a broad stroke of a model’s performance, precision carves out the detail, focusing on the quality of the positive predictions. It is a testament to a model’s capacity not only to detect but also to discern, reflecting a commitment to the truth and reliability demanded in high-stakes decision-making.
Recall – Ensuring Comprehensive Detection
Recall serves as the beacon for comprehensive detection in the landscape of performance metrics. It is the metric that asks not just if our predictions are correct but whether we are capturing all instances of true positives. Recall is defined as the fraction of the total amount of relevant instances that were actually retrieved.
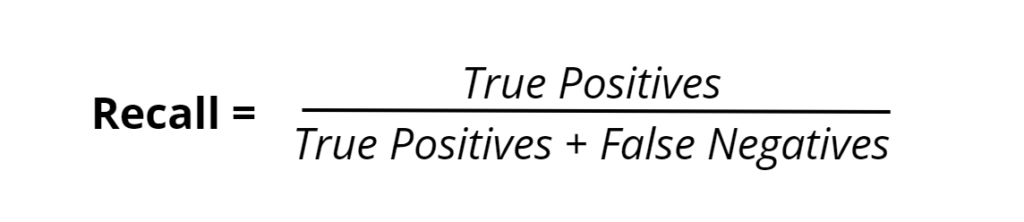
In healthcare, the role of recall cannot be overstated. For conditions such as cancer, failing to identify a positive case (a false negative) could mean a missed opportunity for early intervention, which can significantly impact patient survival rates. Here, a high recall rate ensures that nearly all disease cases are identified, which is imperative.
Similarly, in fraud detection, the cost of not detecting a fraudulent transaction is substantial. While a false positive in this context may lead to customer dissatisfaction, a false negative could mean significant financial losses and damage to institutional credibility. Thus, a model that leans towards a higher recall might be preferable in such fields, even if it risks a few more false positives.
The imperative for recall extends beyond technical accuracy; it echoes the moral responsibility of minimizing harm. In fields where the cost of missing a positive is much higher than the cost of incorrectly identifying one, recall becomes the metric of ethical choice. It is about ensuring that a system is as inclusive as possible of all true cases, embodying the commitment to do good through thorough detection.
The F1 Score – Balancing Precision and Recall
The F1 Score serves as a harmonic balance between precision and recall, providing a single metric that encapsulates both dimensions of a model’s accuracy. It is beneficial in scenarios where an equal weight to false positives and false negatives is critical. The F1 Score is defined as the harmonic mean of precision and recall:
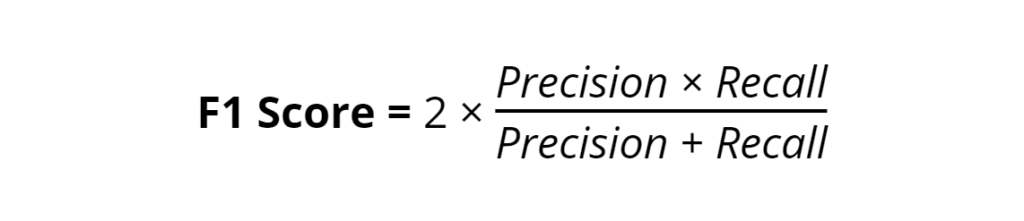
This formula ensures that precision and recall contribute equally to the score, penalizing extreme values where either metric is too low. The F1 Score shines in its use over accuracy, especially in imbalanced datasets where one class significantly outnumbers another. In such cases, accuracy alone might suggest a misleadingly high performance by simply predicting the majority class.
Consider a dataset with a severe class imbalance, such as fraudulent transactions in a large dataset of financial activities. A model might be highly accurate by rarely predicting fraud but miss most fraudulent transactions due to their rarity. Here, a high F1 Score would indicate not only that the model is capturing most fraud cases (high recall) but also that it is not over-flagging legitimate transactions as fraud (high precision).
In essence, the F1 Score transcends the simplicity of accuracy by incorporating the depth of precision and the breadth of recall, thus guiding us toward a more balanced and nuanced evaluation of model performance. It calls for a model not just to identify or exclude but to do both judiciously in pursuit of a more truthful representation of reality in our data-driven decisions.
Comparative Analysis of All Metrics
In the analytical domain, the essence of a model’s evaluation is often distilled into four key metrics: accuracy, precision, recall, and the F1 Score. Each of these metrics offers a unique perspective on the model’s performance, and understanding their interplay is crucial for selecting the most appropriate one based on the specific business problem at hand.
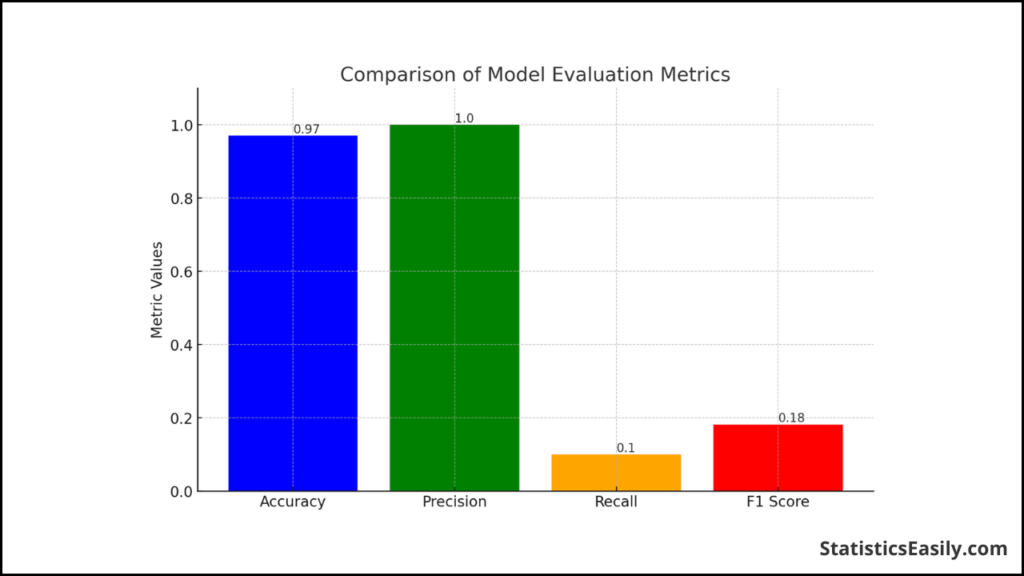
The following bar chart illustrates the differences between these four metrics based on a hypothetical disease prediction model:
| True Condition | Predicted Healthy | Predicted Disease |
|---|---|---|
| Healthy | 980 | 0 |
| Disease | 18 | 2 |
Here is a breakdown of the model’s performance across different metrics:
- Accuracy: 97% – While high, it does not account for our dataset’s gravity of false negatives.
- Precision: 100% – The model’s every positive prediction is correct, but this does not consider the number of missed true positives.
- Recall: 10% – This low score indicates that the model fails to identify 90% of actual positive cases, a critical flaw in specific contexts such as disease diagnosis.
- F1 Score: Approximately 0.18 – This score balances precision and recall, but in this case, it leans towards precision due to the very low recall.
When choosing a metric, one must consider the business implications of false positives and false negatives. In scenarios like healthcare, a high recall is essential to ensure all disease cases are identified despite the risk of false positives. In contrast, precision may be more important in scenarios like spam detection, where false positives (legitimate emails marked as spam) can be highly disruptive.
The F1 Score is particularly insightful when you need a single measure to balance precision and recall. It is especially relevant in imbalanced datasets, where the overrepresentation of one class could skew accuracy.
In summary, while accuracy provides a general idea of model performance, precision, recall, and the F1 Score offer a more nuanced view that can be tailored to the specific needs of a problem. A model’s deployment should be guided by a metric that aligns with the ultimate goal: safeguard human health or protect financial assets, thereby embracing both the scientific rigor and the ethical imperatives of real-world applications.
Conclusion
As we journey through the intricacies of model evaluation metrics, the importance of understanding each metric’s unique attributes and applications becomes evident. Accuracy, precision, recall, and the F1 score illuminate different facets of a model’s performance, offering valuable insights that guide refining our predictive tools.
Accuracy provides a broad overview, yet it may not always capture the nuanced dynamics of model performance, especially in the presence of class imbalances. Precision highlights the model’s ability to minimize false positives, which is crucial when the cost of erroneously labeling an instance is high. On the other hand, recall ensures that the model captures as many true positives as possible, a vital concern in fields like healthcare and fraud detection, where missing a positive instance could have dire consequences. The F1 score harmonizes precision and recall, providing a balanced metric particularly useful in situations where false positives and false negatives carry significant weight.
The “best” metric selection is inherently context-dependent, underscored by the specific demands and implications of the problem at hand. For instance, recall might take precedence in a medical diagnosis scenario to ensure no condition goes undetected. In contrast, precision might be more critical in email spam detection to avoid misclassifying essential messages.
In conclusion, a thoughtful, discerning approach to metric selection is paramount. It requires an alignment with each application’s ethical imperatives and practical realities, ensuring that our models not only predict with accuracy but do so in a manner that upholds the values of truth. This commitment to principled data science empowers us to harness the full potential of our models, driving forward innovations that are not only technically proficient but also ethically sound and contextually relevant.
Ad Title
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Recommended Articles
Delve deeper into data accuracy and model evaluation — discover more articles on these essential topics on our blog.
- 10 Revolutionary Techniques to Master Data Analysis
- 5 Statistics Case Studies That Will Blow Your Mind
- How Statistics Can Change Your Life: A Guide for Beginners
Frequently Asked Questions (FAQs)
Q1: What is accuracy in model evaluation? Accuracy is the proportion of true results (both true positives and true negatives) among the total number of cases examined.
Q2: Why is precision necessary in predictive models? Precision is crucial when the cost of a false positive is high, such as in spam detection, where valid emails could be incorrectly filtered out.
Q3: When is recall the preferred metric? Recall should be prioritized in scenarios where missing an actual positive is detrimental, such as diagnosing severe diseases.
Q4: How does the F1 score help in model assessment? The F1 score balances precision and recall, which is particularly beneficial when dealing with imbalanced datasets.
Q5: Can a model with high accuracy still be flawed? Yes, a model can have high accuracy but still fail to identify positive cases, rendering it ineffective in specific applications.
Q6: Is it better to have higher precision or recall? The preference for higher precision or recall depends on the specific application and the consequences of false positives or negatives.
Q7: What is the difference between accuracy and precision? Accuracy refers to the closeness of the measurements to a specific value. In contrast, precision refers to the closeness of the measurements to each other.
Q8: Can the F1 score be equal to accuracy? The F1 score can sometimes be similar to accuracy. Still, they are distinct metrics and may diverge depending on the dataset’s balance.
Q9: How do you calculate the F1 score? The F1 score is the harmonic mean of precision and recall, calculated as 2 * (precision * recall) / (precision + recall).
Q10: Why might accuracy not be the best metric for a classification model? Accuracy might not be best for skewed datasets where one class significantly outnumbers the other, as the majority class can bias it.





