Outlier Detection and Treatment: A Comprehensive Guide
You will learn the essential techniques for Outlier Detection and Treatment, refining data for truthful insights.
Introduction
In data science, outlier detection and treatment is a critical process that safeguards the integrity and reliability of data analysis. These outliers — data points that deviate markedly from the norm — pose significant challenges, skewing results and leading to incorrect conclusions. Detecting and treating outliers is not just about refining data; it’s about adhering to our scientific endeavors’ principles of accuracy and truthfulness. This guide aims to arm data scientists with the comprehensive knowledge and tools necessary to navigate the complexities of outliers, ensuring that their work reflects the highest standards of statistical integrity and contributes to advancing knowledge in the field.
Highlights
- Outliers can significantly skew data analysis, leading to misleading conclusions.
- Statistical methods like Z-score and IQR are fundamental for detecting outliers.
- Machine learning approaches offer advanced solutions for outlier identification in complex datasets.
- Proper outlier treatment can drastically improve model accuracy and predictive performance.
- Ethical considerations in outlier handling underscore the integrity of data science.
Ad Title
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Understanding Outliers
In data science, outliers are data points that stand apart from a dataset’s collective pattern. These anomalies can significantly impact the overall analysis, leading to skewed results and potentially misleading conclusions. There are primarily three types of outliers: point outliers, which are single data points far away from the rest of the data; contextual outliers, which are data points considered abnormal in a specific context; and collective outliers, where a collection of data points is uncommon compared to the entire dataset.
The theoretical foundation of outlier analysis underscores the vital role that outlier detection and treatment play in maintaining the integrity of data analysis. Outliers can distort statistical measures, such as mean and standard deviation, thereby affecting the outcome of data analysis. For example, a single outlier can significantly shift the mean, which could lead to erroneous conclusions about data trends and behaviors.
Understanding and identifying these outliers is crucial for any robust data analysis process. By acknowledging and addressing outliers appropriately, data scientists can ensure that the conclusions drawn from data analysis are accurate and reflective of the true nature of the underlying data. This step is not just about data cleansing but about preserving the essence of what the data is intended to represent, thereby adhering to the principles of truth and integrity in the scientific process.
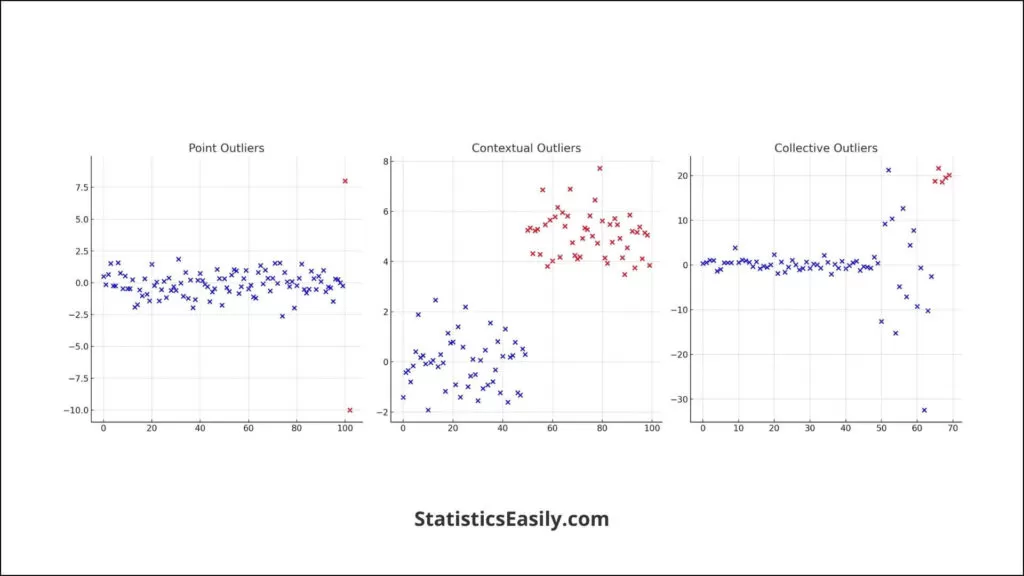
Causes of Outliers
Outliers in datasets can arise from many sources, each necessitating careful consideration for accurate data analysis. Measurement errors are a common cause, where instruments or human error yield data points far removed from the true value. Data entry errors represent another significant source, often due to typographical mistakes or misinterpreting units, leading to anomalously high or low entries. Additionally, natural variability in the data can produce outliers, especially in complex systems where unexpected but genuine extreme values occur.
Consider the case of a scientific experiment measuring a particular chemical concentration. A malfunctioning spectrometer could report an abnormally high concentration, a point outlier resulting from measurement error. In another scenario, a data entry error might introduce an outlier when an extra digit is accidentally added to a reading. Lastly, in a dataset documenting human heights, an exceptionally tall individual represents natural variability, introducing an outlier that is true and reflective of the population’s diversity.
These examples underscore the importance of discerning the nature of outliers. While the instinct may be to remove them, understanding their causes can offer deeper insights. For instance, the outlier in the chemical concentration data prompts equipment checks, ensuring future accuracy. The anomalously tall individual in the height dataset may interest researchers studying genetic factors influencing height.
Hence, eliminating outliers should not be a reflexive process but a thoughtful process, considering the context and cause. This approach ensures that data analysis remains grounded in truth, accurately reflecting the underlying reality and embodying the principles of integrity and thoroughness in scientific inquiry.
Detection Techniques
Detecting outliers is an essential step in data analysis, ensuring the accuracy and reliability of statistical models. Various methods have been developed to identify these anomalies effectively.
Statistical Methods:
Z-score is one of the most common methods for detecting outliers. This technique measures the number of standard deviations a data point is from the mean. Typically, data points with a Z-score beyond ±3 are considered outliers.
Interquartile Range (IQR) involves calculating the range between the first (25th percentile) and the third quartile (75th percentile) of the data. Outliers are then identified as data points that fall below the first quartile or above the third quartile by 1.5 times the IQR.
Grubbs’ Test, the maximum normalized residual test, detects a single outlier in a dataset. This test assumes a normal distribution and is best applied when there is suspicion of only one outlier.
Machine Learning Approaches:
Machine learning provides advanced techniques for identifying outliers in large datasets. Algorithms such as Isolation Forests and DBSCAN (Density-Based Spatial Clustering of Applications with Noise) are particularly effective in detecting anomalies by considering the data’s distribution and density.
Case Studies:
A notable application of outlier detection is fraud detection. Financial institutions use machine learning models to identify unusual transactions that significantly deviate from a customer’s spending patterns and could indicate fraud.
In healthcare, outlier detection methods monitor unusual responses to treatments. For instance, an unexpected adverse reaction to a medication in a clinical trial could be an outlier, signaling the need for further investigation.
The field of environmental science also benefits from outlier detection. Researchers can identify and investigate abnormal changes in climate data, such as sudden spikes in temperature or precipitation levels, to better understand climate change dynamics.
Treatment and Handling Strategies
Identifying outliers is merely the first step in data analysis. How we treat and handle these outliers is a critical decision that significantly influences the outcome and integrity of our study. Strategies for outlier treatment include removal, transformation, and imputation, each with its context of application and implications.
Removal is the most straightforward approach but should be exercised with caution. Eliminating data points can lead to valuable information loss or results bias. This method is generally reserved for clear errors or when an outlier’s influence is disproportionately large compared to its relevance.
Transformation involves applying mathematical functions to reduce the skewness introduced by outliers. Common transformations include log, square root, or reciprocal transformations. This method helps normalize the data distribution, allowing for more effective analysis without directly removing data points.
Imputation replaces outliers with estimated values, typically through median, mean, or regression methods. This strategy is proper when the data point is believed to be erroneous but indicative of an underlying trend that should be addressed.
Ethical Considerations:
The integrity of decision-making in outlier treatment must be balanced. Each strategy has its place, but the choice must be justified ethically and scientifically. Removing a data point because it’s inconvenient challenges the pursuit of truth, as does indiscriminate transformation or imputation without understanding the data’s nature. Ethical practice requires transparency about how outliers are treated and acknowledgment of the potential impact on the analysis’s conclusions.
For example, removing outliers from pollution data without investigating their cause in environmental science could mask significant ecological threats. Similarly, outlier patient responses to treatment in healthcare might reveal crucial insights into side effects or new therapeutic pathways.
Ultimately, the treatment and handling of outliers should not just aim for cleaner data or more comfortable analysis pathways but should reflect a commitment to uncovering and understanding the underlying truths within the data. This commitment ensures that our work advances knowledge with integrity and respect for the phenomena we seek to understand.
Tools and Software for Outlier Detection
Various tools and software have emerged as indispensable allies for data scientists in the quest to identify and manage outliers. These tools, equipped with sophisticated algorithms and user-friendly interfaces, enhance the accuracy of outlier detection and streamline the treatment process, thereby upholding the scientific pursuit of truth.
Python Libraries:
- Scikit-learn: Renowned for its comprehensive machine learning capabilities, scikit-learn offers practical methods for outlier detection, such as Isolation Forest and Local Outlier Factor (LOF). Its versatility and ease of integration make it a staple in the data scientist’s toolkit.
- PyOD: A specialized library dedicated to outlier detection, PyOD includes a wide array of detection algorithms, from classical approaches like ABOD (Angle-Based Outlier Detection) to contemporary neural network-based models. PyOD’s consistent API and integration with scikit-learn facilitate a seamless analysis experience.
R Packages:
- OutlierDetection: This package provides tools to detect and handle outliers in univariate and multivariate data. It is particularly valued for its robust statistical techniques and adaptability to various data types.
- mvoutlier: Specializing in multivariate data, mvoutlier offers graphical and statistical methods for identifying outliers. It is an essential tool for complex datasets where outliers may take time to be obvious.
Software Platforms:
- KNIME: A graphical user interface-based software that enables sophisticated data analysis workflows, including outlier detection. Its modular structure incorporates classical statistical methods and advanced machine-learning algorithms.
- Tableau: Known for its data visualization prowess, Tableau also includes features for outlier detection, primarily through visual analysis. This capability allows users to quickly identify anomalies within large datasets by observing deviations in graphical representations.
—
The Role of Outliers in Predictive Modeling and Machine Learning
Outliers hold a nuanced position in predictive modeling and machine learning, impacting model accuracy and predictive performance in significant ways. Understanding their role is crucial for developing robust and aligned models with the truth of the data they represent.
Impact on Model Accuracy and Performance
Outliers can dramatically influence the training process of predictive models. For example, outliers can skew the regression line in linear regression models, leading to poor model performance on the general dataset. In clustering algorithms, outliers can alter cluster centers, affecting the model’s ability to accurately group data points.
Handling Outliers in Model Training
The approach to handling outliers must be considered carefully during model training. Options include:
- Exclusion: Removing outliers from the dataset before training, which can be appropriate when outliers are confirmed errors with no underlying significance.
- Transformation: Applying mathematical transformations to reduce the range of data points makes outliers less pronounced and potentially improves model robustness without outright removal.
- Robust Methods: Utilizing models and algorithms designed to be less sensitive to outliers, such as random forests or robust regression methods.
Ensuring Models are Robust and Truthful
The integrity of model training lies in balancing the elimination of noise with the preservation of valuable data. Genuine variability-related outliers should not be hastily removed but instead understood for the insights they may offer. This understanding can lead to models that are more accurate and more reflective of the complexity and truth of the underlying phenomena.
Guidance for Handling Outliers
- Analysis and Documentation: Thoroughly analyze outliers to determine their cause and document decisions made regarding their handling.
- Validation: Use cross-validation techniques to ensure that the model performs well on unseen data and that outlier handling strategies improve the model’s generalizability.
- Continuous Monitoring: Even after deployment, models should be continuously monitored to ensure they remain effective as new data is introduced, which may contain new and informative outliers.
Ad Title
Ad description. Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Conclusion
The journey through outlier detection and treatment is key in data science, ensuring the integrity and reliability of data analysis. It is a testament to the dedication of data scientists to achieving accuracy and upholding the truth within their scientific efforts. As we have explored, the careful identification, analysis, and treatment of outliers not only refines our data but also deepens our understanding, revealing insights that might otherwise remain obscured. This comprehensive guide underscores the necessity of approaching outliers with a balance of technical knowledge and ethical consideration, aligning our practices with the more excellent pursuit of revealing the truth in data. Let this guide inspire a continued quest for knowledge and the application of ethical principles in outlier treatment, fostering a culture of integrity and thoroughness in the scientific community.
Recommended Articles
Explore more about refining your analytical prowess. Read our related articles on advanced data science techniques and elevate your knowledge today!
- Navigating the Basics of Generalized Linear Models: A Comprehensive Introduction
- Accuracy, Precision, Recall, or F1: Which Metric Prevails?
- Histogram Skewed Right: Asymmetrical Data (Story)
- Master Paired t-Tests (Story)
- Example of Paired t-Test
Frequently Asked Questions (FAQs)
Q1: What exactly are outliers in data analysis? Outliers are data points that differ significantly from other observations, potentially distorting statistical analyses and results.
Q2: Why is Outlier Detection and Treatment important? Identifying and treating outliers is crucial for accurate data analysis, ensuring models reflect true underlying patterns.
Q3: Can outliers ever be considered valuable data points? Outliers can reveal new insights or errors in data collection, and their interpretation often requires careful analysis.
Q4: What are standard methods for detecting outliers? Z-score and Interquartile Range (IQR) are popular statistical methods.
Q5: How do machine learning models handle outliers? Depending on the algorithm, machine learning models may require preprocessing to minimize outlier impact or inherently accommodate outliers.
Q6: What is the impact of outliers on predictive modeling? Outliers can skew model predictions if not adequately addressed, leading to less accurate or biased results.
Q7: Are there automated tools for outlier detection? Several software tools and packages are designed specifically to detect and treat outliers in datasets.
Q8: How does outlier treatment vary by data type? Treatment strategies may include data transformation, removal, or imputation, depending on the data’s nature and analysis goals.
Q9: What ethical considerations arise in outlier treatment? Ethical considerations include ensuring data integrity and avoiding manipulation that could bias results or conclusions.
Q10: How can I further my knowledge in Outlier Detection and Treatment? Engaging with advanced data science courses, tutorials, and practical projects can deepen understanding and skill in outlier analysis.